About Me
Hello, I'm Michelle! I am currently pursuing my B.Sc. in Computer Science (Honours with a Data Science option) at the University of Ottawa. I'm passionate about data science, machine learning, fullstack development, and system design. I'm also part of the CO-OP program and have hands-on experience in both frontend and backend technologies. Outside of my academics and career-based pursuits, I'm the vice president of my university's powerlifting club, I like to 3D model in Blender and Nomad, and I like to draw using digital and traditional mediums.

How I Work
-
Understand needs
In software engineering, I understand that the specifications of a project follow from a business problem. Thus, when I am performing the main activities of the requirements engineering process, I will determine what the functional and nonfunctional requirements are, assess what is feasible given the business problem and existing technologies, and then identify both system and user-based requirements.
-
Plan a solution
Here, I think about what technologies, programming paradigms, and libraries the project requires. I will reflect on my relevant coursework, past projects, and work experience in order to begin planning the solution. I may produce UML diagrams, data flow diagrams, and other state-based diagrams to determine the behavior of the product.
-
Implement the solution
I will then implement the solution. Depending on what paradigms are involved, this will look different from project to project. If I am working with object-oriented programming principles, I will begin by implementing classes at the top of the hierarchy and then implementing their subclasses, testing their functionalities as I go along or leaving unimplemented classes as stubs. If I am working on a project that uses concurrency, I would approach the problem by identifying independent tasks that can be run in parallel and managing shared resources carefully using synchronization techniques.
-
Testing and maintainability
During the implementation process is typically when I write test cases. As I am designing classes, that is when I can understand how to produce equivalence classes for the most effective test case generation. I will review my code and identify any redundant functions or interdependencies that could hamper scalability.
-
Documentation
Again, as I go along with implementing the solution, I will make notes of any bugs or errors and include them in the documentation. I typically produce a guide on how to use the software while implementing the solution, but if any large changes are made, I will refine the instructions at the end of the project.
In software engineering, I understand that the specifications of a project follow from a business problem. Thus, when I am performing the main activities of the requirements engineering process, I will determine what the functional and nonfunctional requirements are, assess what is feasible given the business problem and existing technologies, and then identify both system and user-based requirements.
Here, I think about what technologies, programming paradigms, and libraries the project requires. I will reflect on my relevant coursework, past projects, and work experience in order to begin planning the solution. I may produce UML diagrams, data flow diagrams, and other state-based diagrams to determine the behavior of the product.
I will then implement the solution. Depending on what paradigms are involved, this will look different from project to project. If I am working with object-oriented programming principles, I will begin by implementing classes at the top of the hierarchy and then implementing their subclasses, testing their functionalities as I go along or leaving unimplemented classes as stubs. If I am working on a project that uses concurrency, I would approach the problem by identifying independent tasks that can be run in parallel and managing shared resources carefully using synchronization techniques.
During the implementation process is typically when I write test cases. As I am designing classes, that is when I can understand how to produce equivalence classes for the most effective test case generation. I will review my code and identify any redundant functions or interdependencies that could hamper scalability.
Again, as I go along with implementing the solution, I will make notes of any bugs or errors and include them in the documentation. I typically produce a guide on how to use the software while implementing the solution, but if any large changes are made, I will refine the instructions at the end of the project.
Projects
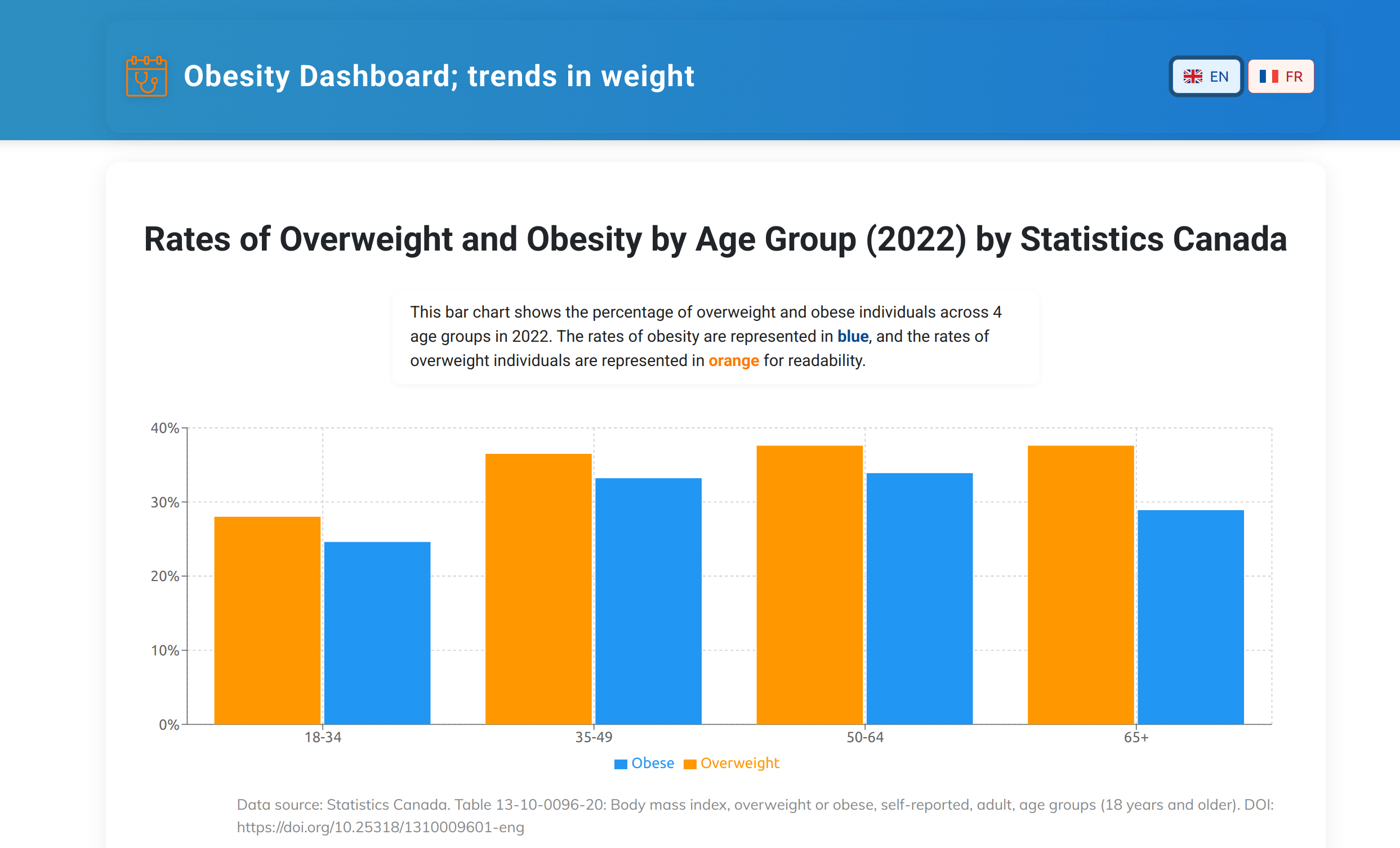
Displayed below are my projects for SEG3125, developed during my Summer 2025 semester. Click one of the projects to visit their pages, or just read their descriptions listed here. Each description includes an overview of the project's implementation, relevant technologies, and purpose.